Update: Das Projekt ist Mitte 2023 aufgrund von API-Änderungen nach der Übernahme leider in den vorzeitigen Ruhezustand geschickt worden. Weiteres zu dem Ende von Chirpanalytica findet sich in dem entsprechend in dem Abschieds-Beitrag.
Im folgenden der unveränderte Beitrag zur Veröffentlichung von Chirpanalytica:
Mit den letzten 100 Tweets eines Accounts bestimmen, welcher politischen Partei die Person hinter dem Benutzerkonto am nächsten steht – eine simple Idee, mit welcher ich mich seit knapp zwei Jahren beschäftige.
Unzählige Stunden Arbeit und die Hilfe vieler verschiedener Personen später präsentiere ich Chirpanalytica – der Wahl-O-Mat für Twitterkonten.
Eine Vorgeschichte
Auch wenn ich an dem Projekt seit nun fast zwei Jahran arbeite, ist die Idee hinter dem Projekt schon deutlich älter als diese Zeit: Auf Jugend hackt 2017 in Frankfurt am Main wurde an einem Wochenende der “Profil-O-Mat” geboren. Auch wenn ich kein direkter Teil der Projektgruppe war (ich half zwar etwas beim Frontend, besaß aber nicht das technische Verständnis, um tatsächlich richtig mithelfen zu können und arbeitete deshalb lieber an einem Twitter-Minispiel), faszinierte mich damals schon die Idee und die an einem Wochenende erreichte Genauigkeit.
Nachdem (wie leider viele Hackathon-Projekte, da die Rechenleistung auf Dauer zu teuer wird) der Profil-O-Mat kurz nach dem Hackathon offline ging, fasste ich den Gedanken, die Projektidee wieder zum Leben zu erwecken.
Leider wurde mit dem Offline-Nehmen des Projektes auch das GitHub-Repository und alle weiteren Projektteile gelöscht, sodass nur noch die Teile des Projektes, bei denen ich mitgeholfen habe. Dazu kam noch das Twitter-API-Update auf die Version 2 dazu, welches Rate-Limits einführte und damit ein Weiterleben des Projektes zusätzlich erschwerte.
Trotzdem machte ich mich an die Arbeit, ein Konzept für das neugetaufte Chirpanalytica-Projekt (der Name ist an den Facebook Cambride Analytica-Skandal mit Augenzwinkern angelehnt) zu erstellen – ohne zu wissen, welche Arbeit damit auf mich zu kam.

Wir brauchen Daten, Chef!
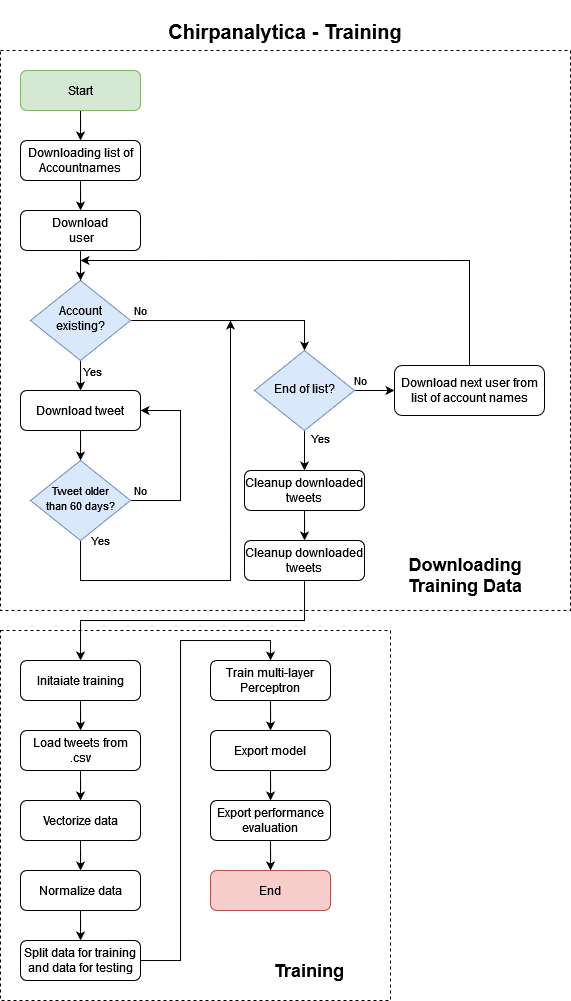
Die erste Aufgabe war es bei dem Projekt, einen Trainingsdatensatz für das neuronale Netz zu generieren. Dabei sollten mehr als 7.000 Tweets von verschiedenen Parteien (SPD, Union, FDP, AfD, DIE LINKE, Bündnis 90/Die Grünen und die Piratenpartei) gesammelt werden, komplett automatisierbar und möglicht übersichtlich.
Ich began damit mir zu überlegen, wie ich überhaupt an die Namen der Twitter-Accounts kommen könnte. Nachdem ich alle möglichen Ideen von einer händischen Liste bis hin zu einem scraping-tool für die Mandatsträgerübersicht des deutschen Bundestags ausprobiert hatte, wurde ich auf eine sehr spannende Idee gebracht: Auf Wikidata kann man selber Abfragen bauen und damit den Datenabruf bestimmter Eigenschaften von Personen einfach gestalten.
Nach einer ganzen Menge Herumprobieren und Hilfe durch Martin (dazu in der Dankesagung ganz unten mehr) kam ich auf eine Query-Funktion, mit der man alle auf Wikidata eingetragenen Twitter-Accounts deutscher Politiker der oben genannten Parteien herunter laden konnte:
Mit dieser Query erhielt ich über eine cURL-Abfrage eine .csv mit den benötigten Daten, um in einem Python-Skript die Personen einzulesen. Damit konnte ich beginnen, mich um den Download der tatsächlichen Tweets zu kümmern. Nach vielen, vielen Stunden Arbeit (größtenteils wegen Library-Problemen, da viele noch nicht richtig mit der Twitter API Version 2 umgehen konnten) kam ich zu einem halbwegs zufriedenstellenden Ergebnis, welches die Funktion des Daten-Downloads erfüllte. Der größte Nachteil an der Implementierung wie in diesem Ergebnis über Tweepy war – und ist weiterhin – die sehr zeitintensive Ausführung: Für den Download der letzten 200 Tweets von 900 Accounts braucht der Downloader mehr als 21 Stunden. Immerhin ist das Ergebnis sehr lohnenswert: 70.000 Tweets in einer Datei, übersichtlich als Comma-separated values zusammengestellt mit Account-Name und zugehöriger Fraktion.

Trainieren macht den Meister
Mit diesem Datensatz ging es an das Training des Projektdatensatzes. Nach ersten Versuchen in dem Framework TensorFlow stellte ich fest, dass dieses nicht wirklich geeignet war für den Anwendungszweck der neuronalen Textverarbeitung. Im Nachhinein habe ich mich wohl etwas zu schnell von der riesigen Dokumentation einschüchtern lassen, so gibt es doch sehr vielversprechende Projekte zu TensorFlow und NLP (Neuronal Language Processing).
Nach Tensorflow testete ich noch etwas in Pytorch herum, kam von da aber schnell zu scikit-learn: Die bekannte und umfangreiche Bibilothek baut wiederrum auf den Bibliotheken NumPy und SciPy auf, sodass der Einstieg mit etwas NumPy-Erfahrung nicht zu komplex war.
An ein paar Wochenenden konnte ich mit etwas Starthilfe von verschiedenen Beispielen und Überbleibseln des “Profil-O-Mat[en]” das Training wieder zum Laufen bekommen. Ich werde hier nicht sehr tief in die Thematik des deep leanings einsteigen (vielleicht kommt dazu mal ein extra Blogbeitrag), im Großen und Ganzen werden die Daten erst vorbereitet und aufgeteilt, bevor der mehrlagige Perzeptron-Klassifizierer (eingedeutscht von Multi-layer Perceptron classifier) seine Arbeit verrichtet und sich danach gegen sich selber testet. Am Ende der mehrstündigen Trainingsphase steht das exportierte Netzwerk und die Leistungsevaluation zur Verfügung.
Während der Zeit, in der ich an dem Anlernen des neuronalen Netzwerks arbeitete, kam Torben, einer der damaligen Projektmitstreiter und Freund von mir, zu dem Projekt dazu und unterstützte mich direkt bei der korrekten Vorbereitung der Daten: Ich hatte das Problem, durch eine falsche Matrix-Konvertierung für jeden Tweet eine eigene Partei anzulegen und damit ein ziemliches Chaos beim Training zu verantworten.
Im Februar 2021 stand damit das Training wieder und es war mir möglich, erste Sätze zu analysieren.
▼(Klick) Beispiel Leistungsevaluation
Evaluating performance...
Training error: 0.05285329139519209
Test error: 0.43669961806335655
Training data:
precision recall f1-score support
Freie Demokratische Partei 0.94 0.99 0.96 3240
Alternative für Deutschland 0.95 0.78 0.86 1310
Christlich Demokratische Union Deutschlands 0.94 0.98 0.96 6021
Piratenpartei Deutschland 0.85 0.76 0.81 1607
Sozialdemokratische Partei Deutschlands 0.91 0.98 0.95 7102
Die Linke 0.99 0.91 0.95 3723
Bündnis 90/Die Grünen 0.97 0.96 0.96 12605
accuracy 0.95 35608
macro avg 0.94 0.91 0.92 35608
weighted avg 0.95 0.95 0.95 35608
Test data:
precision recall f1-score support
Freie Demokratische Partei 0.51 0.45 0.48 1606
Alternative für Deutschland 0.38 0.35 0.36 679
Christlich Demokratische Union Deutschlands 0.55 0.60 0.57 3009
Piratenpartei Deutschland 0.25 0.25 0.25 863
Sozialdemokratische Partei Deutschlands 0.50 0.55 0.52 3434
Die Linke 0.57 0.49 0.52 1889
Bündnis 90/Die Grünen 0.69 0.67 0.68 6324
accuracy 0.56 17804
macro avg 0.49 0.48 0.48 17804
weighted avg 0.56 0.56 0.56 17804
Frontend und Twitter-Bots, oder: Der Crunch vor der Bundestagswahl 2021
Nachdem Ende Februar das trainierte Netzwerk stand, musste ich das Projekt erst einmal für ein paar Monate auf der Prioritäten-Liste nach unten rutschen: Neben Wettbewerben und Reisen hatte ich wenig Zeit, an Chirpanalytica weiter zu arbeiten.
Nach den Sommerferien stieg ich dafür jedoch wieder in das Projekt ein, und dieses Mal mit mehr Elan den je: Die kommende Bundestagswahl setzte mir ein festes “Abgabedatum”, zu welchem ich die Version 1 gerne veröffentlicht hätte.
Also begann ich, das Projekt in die Zielgrade zu führen: Erst ein Python-Skript zur Accountvorhersage bauen, dann wieder einen Webserver zum Laufen bekommen, der nach Mitteilung des gewünschten Nutzeraccounts per Query-String die Parteiübereinstimmungen als JSON zurücklieferte.
Als Nächstes musste das Frontend gebaut und getestet werden, dazu erstellte ich ein Logo und kümmerte mich um den Twitter-Bot.
Diesen Twitter-Bot schrieb ich in einer Nachtschicht in Python. Der Chirpbot (so wurde er getauft) ist dabei vollständig getrennt vom Backend des Chirpanalytica-Projektes und läuft selbständig als Service auf meinem Server.
So entstand in zwei Wochen ein ziemlich großer Fortschritt an dem Projekt, ich arbeitete circa 5-7 Stunden am Tag an der Fertigstellung von Chirpanalytica. In all den Stunden sind sowohl sehr angenehme Erfahrungen wie auch nerventreibende Webbrowser-Probleme aufgetreten. CORS-Abfragen (Cross-Origin Resource Sharing) haben mir Schweiß und Tränen bereitet, da war die Arbeit an dem folgenden GIF eine willkommene Abwechselnung:

Deine Tweets stimmen so viel mit den den folgenden Parteien überein:
— Chirpanalytica - Der Wahl-O-Mat für Gezwitscher (@chirpanalytica) September 23, 2021
⬛ CDU: 10.7%
🟥 SPD: 22.0%
🟨 FDP: 11.6%
🟥 Die Linke: 4.2%
🟩 Die Grünen: 32.0%
🟧 Piratenpartei: 17.5%
🟦 AfD: 2.1%
Insgesamt haben wir 49 Tweets von dir analysiert.
Zu guter Letzt half mir Torben nochmal ein gutes Stück durch Unterstützung beim Aufräumen des Codes und der Responsive-Auslegung des Frontends. Damit war in der Woche vor der Bundestagswahl Chirpanalytica in seiner Version 1.0 endlich einsatzbereit.
Das Ergebnis: Flieg Vogel, flieg!
Nach vielen Nachtschichten (so ist auch dieser Beitrag in einer entstanden) bin ich glücklich, Chirpanalytica vorstellen zu können: Durch Eingabe eines Twitter-Benutzernamens auf https://de.chirpanalytica.com/, durch Erwähnung von @chirpanalytica auf Twitter oder durch Bedienung des Fensters unter diesem Absatz erhält man ganz unkompliziert die Daten zu den Parteien, die mit der politischen Ausrichtung des Benutzers die meisten Übereinstimmungen haben . Dabei ist es wichtig, dass der Twitter-Account Inhalte auf Deutsch schreibt und so aktiv wie möglich ist.
Und nun: Viel Spaß mit Chirpanalytica!
Eine Dankesagung
Ich bin es schuldig, den Personen, ohne die das Projekt nicht in dieser Form möglich gewesen wäre, zu danken:
Allen voran die Jugend hackt-Projektgruppe des “Profi-O-Mat[s]” von Jugend hackt Frankfurt am Main 2017, die einen tolles Proof of Concept und eine Grundstruktur für das Projekt geliefert haben: Adrian, Levy, Bela, Niklas, Philipp und Torben.
Bei Torben kann ich mich gleich noch ein weiteres Mal bedanken: Ohne sein Mitarbeiten bei Chiranalytica wäre es nicht möglich gewesen, das Projekt zum Laufen zu bekommen. Vielen Dank, Torben!
Außerdem kann ich mich bei Martin bedanken für die Hilfe bei der Erstellung der Wikidata-Query, um die Twitter-Accounts der Politiker zu erhalten.
7 Current Opinions
Hallo Paul,
Wie sieht der Input-Vektor aus?
Hallo Martin,
genau ist das in der Train.py-Datei von Chirpanalytica zu finden.
Im Endeffekt werden fractions und tweets in vektorisierter Form und nach ein bisschen Daten-Shaping (shuffling, testdaten abzwacken) normalisiert direkt in den MLP-Classifier gepackt.
Beste Grüße,
Paul
Die Datei versteh Ich leider nicht. Das Problem ist wenn man die politischer Position in der Wortwahl ergründet. Da nicht jeder Tweet politisch aussagekräftig ist, denke Ich mal du hast einen Filter in Form eines weiteren Neuronalen Netzes dafür verwendet. Der eben politische Tweets erkennt.
Ah, das meinst du: Nein, das neuronale Netzwerk bekommt nicht nur politische Tweets, sondern einfach einen bunten Mix aus allen möglichen Tweets von Politikern. Das coole ist an dem System, das auch Aussagen wie “ich gehe heute eine Radtour machen” politisch gewertet werden können. Die Tweets werden nur in dem Sinne sortiert, dass die mindestens 4 Zeichen haben müssen, nachdem Stoppzeichen und weitere unnötige Wortteile abgeschnitten wurden. Das neutonale Netzwerk macht dann nichts weiter, um nur die politischen Tweets zu analysieren.
Habe einen Test mit einem alten Twitter Acc (https://twitter.com/critiCritics) gemacht. Habe Parteien angezeigt bekommen trotz objektiven Tweets. Was wenn Chirpanalytica größtenteils die Wortwahl gewichtet? Ist es möglich das Modell darauf zu untersuchen?
Der Twitter Account ist leider viel zu wenig aktiv, um da überhaupt was vorhersagen zu können – der einzige Tweet, der am Ende analysiert wird ist vom 12. September und auf Englisch, damit kann das Modell nicht umgehen.
Die Wortwahl spielt aber auch eine Rolle sicherlich, neben dem Kontext in dem diese Wörter aufkommen. Das Modell kann man nicht direkt untersuchen, nur durch viel Testen und herumprobieren kann man da Schlüsse ziehen.