Meross trifft InfluxDB: Ein Leitfaden zum Import von Energieverbrauchsdaten smarter Meross-Zwischensteckdosen
Mit meinem Umzug nach Hamburg hatte ich endlich eine Chance, ein richtiges Smart-Home-Setup auszusetzen. Dabei verfolgte ich folgende Strategie: Simpel Daten verwalten und zukunftssicher Daten sammeln. Bei einem klassischen Studenten-Budget lief das mit darauf hinaus, zum einen eigene Smarthome-Geräte zu entwerfen und zum anderen bereits gekaufte Geräte weiterzuverwenden.
Letzerer Punkt hatte zur Folge, dass ich Meross-Smart-Home-Zwischensteckdosen mit Strommessung des Typen "mss310" verwenden wollte. Diese Zwischensteckdosen schmeißen jedoch ihre Daten nur in eine proprietäre App - und ohne Apple HomeKit-Integration war ein verwenden dieser Steckdosen für mich auf den ersten Blick nicht Sinnvoll.
Ein zweiter Blick offenbarte jedoch, dass ich augenscheinlich nicht die erste Person mit diesem Hintergrund war, denn zumindest für das Datenproblem gab es bereits Adapter, welche die Daten über die Meross API scrapten und in eine time-series Database (TSDB, kurz: InfluxDB) schreibt. Etwas tiefer gegraben ergab leider auch, dass diese inzwischen nichtmehr Funktionsfähig war.
So beschloss ich, einen eigenen Adapter zu schreiben, welcher die Daten von der Meross-API abholt und in InfluxDB schreibt. Dabei machte ich auch erstmalige Erfahrungen mit dem veröffentlichen von Docker-Images auf dem Docker hub, all dies Dokumentiere ich hier in diesem Beitrag.
TL;DR: Das Setup
Wenn du einfach nur möglichst schnell das Projekt zum laufen bekommen möchtest, ist dieser Abschnitt für dich: Einmal die kondensierte Anleitung zum Setup mit Docker via compose und einer bereits vorhandenen standalone InfluxDB-Instanz: Dabei gehe ich davon aus, dass du einen Linux-Server mit APT als Paketmanager hast. Wenn du 24/7 Daten von deinen Steckdosen sammeln willst, achte darauf, dass der Server natürlich auch 24/7 mit dem Internet verbunden sein muss.
Docker sollte bereits installiert sein, sollte dies nicht der Fall sein, kann das mit
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install -y docker-ce
nachgeholt werden.
Dann muss nur noch ein neues Verzeichnis (z.B. "docker2influxdb") angelegt werden, darin wiederum eine Datei mit dem Namen "docker-compose.yml" angelegt werden, der Inhalt kann von dieser Vorlage übernommen werden:
In der Vorlage müssen aber natürlich noch die Umgebungsvariablen angepasst werden: Da wären zum einen die Zugangsdaten vom Meross-Account, die Server-Region für die Meross-API (für Europa iotx-eu.meross.com) und dann die Token-Konfiguration für deine InfluxDB-Instanz. Zu Guter letzt fehlt noch eine Liste jener Geräte, die du gern überwachen würdest. Solltest du dir unsicher über die Gerätenamen sein, schaue lasse einmal mit
docker compose up
den Container starten. Du solltest, solange die Zugangsdaten für Meross stimmen, die im Account gefindenen Geräte aufgelistet sehen. Wenn diese Daten alle eingetragen sind, kann mit
docker compose up -d
der Container gestartet werden.
Mit
docker logs MerossToInfluxDB
kann überprüft werden, ob der connector richtig arbeitet.
Im bestenfall siehst du ab dem Zeitpunkt in deiner InfluxDB-Installation, das die Verbrauchsdaten von Meross in dem zuvor erstellten Bucket landen.
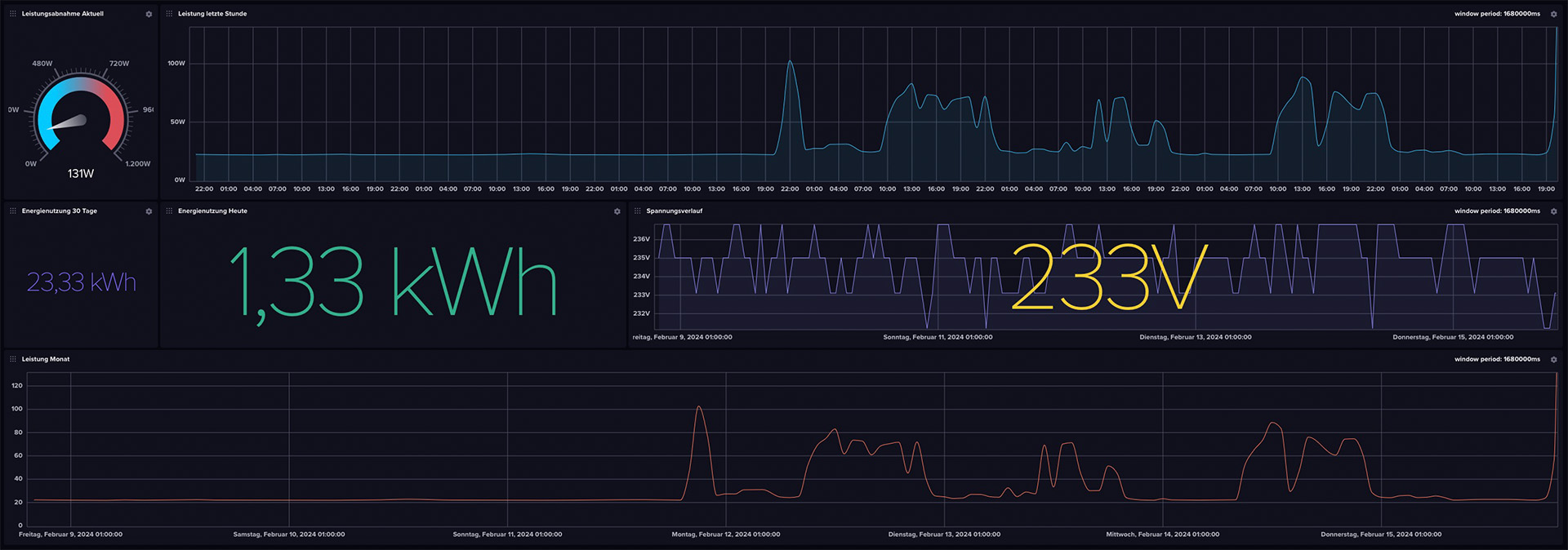
Das Dashboard
Wenn die Daten im Bucket ankommen, wäre es ja traurig, nichts mit den Daten anzufangen. Deshalb habe ich ein minimales, mit leichten Problemen behatetes Dashboard zusammengeklickt. Dieses kann im GitHub-Repository sowie unter diesem Direktlink heruntergeladen und in influxDB eingespielt werden.
Docker-Images im Selbstbau
Mit dem Projekt konnte ich einen spannenden ersten Einstieg in das Deployment von Docker Images auf dem Docker Hub machen. Die entwicklung von Docker Images startet immer mit dem erstellen eines Dockerfiles. In diesem werden die Schritte bestimmt, die das spätere Image bestimmen. Eignetlich also ein Kochrezept für den Zusammenbau in chronologischer Reihenfolge. Los geht es mit einem Base Image, in dem Fall dieses Projektes Python 3.9 in der besonders speicherplatz-sparenden Alpine-Edition. Dieses wird mit dem directive
FROM python:3.9-alpine bestimmt. Danach wird die requirements.txt-Datei, in der die benötigten Libraries für das Projekt (meross-iot>=0.4.2.0 & influxdb-client>=1.22.0) hinterlegt sind. Nun wird mit ARG die definierbaren Umgebungsvariablen erst initalisiert, dann mit ENV verlinkt.Als nächstes wird mit # Install necessary system dependencies
RUN apk update && apk add --no-cache
gcc
libc-dev
libffi-dev
einmal dem Problem begegnet, dass Meross2InfluxDB beim Start aufgrund nichtgefundender Dependencies direkt wieder abstürzt. Als nächstes wird setuptools und wheel von pip geupdated, dann werden die zuvor kopierten requirements.txt installiert. Der eigentliche Connector wird kopiert und ausgeführt, als letztes wird noch das health-script, welches regelmäßig die Verbindung zu der Meross-API prüft, in den Contianer geladen und als Healthcheck hinterlegt.
All das kann dann mit
docker buildx build --platform linux/amd64,linux/arm64,linux/arm/v7 -t quantensittich/meross2influxdb:latest --push .
direkt für mehrere Plattformen gebaut und auf dem Docker-Hub veröffentlicht werden. Achtung: Dockerx braucht für den Bau für mehrere Plattformen sehr lange - selbst auf einem NASA-PC braucht der zusammenbau und das Publishen für die Plattformen amd64, arm64 und armv7 (jeweils nur Linux!) schon 10 Minuten. Mit mehr Plattformen skaliert diese Zeit entsprechend weiter. Nachdem DockerX mit "pushing manifest" den Prozess beendet hat, konnte das Projekt auf dem Docker-Hub gefunden werden.
"API Limits? Nicht mit uns!"

Obwohl ich es nicht explizit ausprobiert habe, scheint es so, als gäbe es kaum ein Rate Limit bei der API von Meross: Bei 12.960 API-Requests (3/Minute mit drei Devices) pro Tag gibt es kein Anzeichen von rate Limiting nach mehreren Wochen ansturm.
Nach den DNS-Aufzeichnungen der Meross-API nutzt die Firma im Hintergrund die Amazon Web Services, um die Daten zu verwalten - meinen groben Überschlägen kostet Meross in AWS-Rechenzeit dieser Spaß pro Jahr etwa 3 Euro. Sicherlich nicht viel für eine Firma wie Meross (Chengdu Meross Technology Co., Ltd.), aber bie einem Stückpreis von etwa 15 Euro ist nach fünf Jahren der API-Requests der gesamte Umsatz in AWS-Serverkosten verbrannt.
Der Fiebertraum der Query-Sprache "Flux"
Ein Laster schleppe ich seit meinen ersten Versuchen mit InfluxDB im Jahr 2019 und der darin integrierten DB-Query-Sprache "Flux" bis heute: Ich tue mich unglaublich schwer, gefallen an Flux zu finden. So versuchte ich, ein simples Script zu schreiben, welches den Stromverbrauch pro Tag ausrechnet. Das müsste mit einer einfachen Integration der Fläche unter dem Graphen im gewünschten Zeitraum getan sein. In Python vielleicht fünf Minuten arbeit, in Flux konnte ich auch nach zwei Stunden des Testens keinen richtigen Ansatz finden, meinen Plan in die Tat umzusetzen.
from(bucket: "meross_ingress") |> range(start: -1d) |> filter(fn: (r) => r["_measurement"] == "meross_data") |> filter(fn: (r) => r["_field"] == "power") |> filter(fn: (r) => r["device"] == "Schreibtisch") |> aggregateWindow(every: 20s, fn: sum, createEmpty: false) |> map(fn: (r) => ({ r with _value: r._value / 104.0 })) |> yield(name: "sum")
Diese Abfrage liefert zwar einen Wert, der dem Tagesstromverbrauch nahe kommt, aber weicht (wahrscheinlich wegen dem festen Teiler von 104) mal mehr, mal weniger ab von dem eigentlichen Ziel - wenn jemand von euch Erfahrung mit Flux hat, gebt gern bescheid, wenn ihr meinen Fehler in dem Skript seht!
Update, 11.06.2024
Es hat sich gezeigt, dass es Sinnvoll ist, für den dauerhaften Docker-Betrieb einmal am Tag den Container neu zu starten, zum Beispiel per Cronjob:
crontab -e
0 0 * * * cd /pfad/zur/docker-compose.yml && /usr/bin/docker compose down && /usr/bin/docker compose up -d
Woher dieses Problem kommt, versuche ich aktuell herauszufinden. Bis dahin ist ein solcher Cronjob nur sinnvoll.